使用Nagios打造专业的业务状态监控
想必各个公司都有部署zabbix之类的监控系统来监控服务器的资源使用情况、各服务的运行状态,是否这种监控就足够了呢?有没有遇到监控系统一切正常确发现项目无法正常对外提供服务的情况呢?本篇文章聊聊我们如何简单的使用Nagios监控业务的状态
文中的业务指用户访问的网站页面,对外提供的API接口,移动端的APP等产品
监控的思考
通常我们会在项目所在的机房部署一套监控系统来监控我们服务器和MySQL之类的公共服务,制定报警策略,在出现异常情况的时候邮件或短信提醒我们及时处理。
此类监控主要的关注点有两个:
- 资源的占用情况,例如负载高低、内存大小、磁盘空间等
- 服务的状态监控,例如Nginx状态、Mysql主从状态等
同时也会存在以下两个主要问题:
- 缺少业务状态的监控,不能很直观的知道业务当前的状态,可能服务器、服务都正常但业务确挂了
- 监控服务器和业务服务器处于同一机房环境内,监控网络故障、入口网络拥堵等情况都可能会导致收不到监控系统的报警,且只能监控机房内的情况,用户到机房入口的情况无法监控
那么如何解决这两个问题呢?
业务状态监控,就是要最直观的的反映业务当前是正常还是故障,该怎么监控呢?以web项目为例,首先就是要确定具体URL的返回状态,是200正常还是404未找到等,其次要考虑页面里边的内容是不是正常,我们知道最终反馈给用户内容的是由一些静态资源和后端接口数据共同组成的HTML页面,想知道内容究竟对不对这个比较困难,退而求其次我们默认所有静态资源和后端接口都返回正常状态则表示正常,这个监控就比较容易实现了。
静态资源可以直接由nginx服务器处理,nginx的并发能力很强,一般不会成为性能的瓶颈,针对静态资源的监控我们可以结合ELK一起来看。后端接口的处理性能就要差很多了,对业务状态的监控也主要是对后端接口状态的监控,那我们是否需要监控所有的接口呢?这个实施起来比较麻烦,我觉得没太大必要,只需要监控几个有代表性的接口就可以了,例如我们所有的项目中都让开发单独加了一个health check的接口,这个接口的作用是连接项目所有用到的服务进行操作,如接口连接mysql进行数据查询以确定mysql能给正常提供服务,连接redis进行get、set操作以确定redis服务正常,对于这个接口的监控就能覆盖到整个链路的服务情况。
对于监控服务器和业务服务器在同一个机房内所导致的问题(上边讲到的第二点问题),我们可以通过在不同的网络环境内部署独立的状态监控来解决,例如办公区部署Nagios,不同网络监控也更接近用户的网络情况,这套状态监控就区别于机房部署的资源占用监控了,主要用来监控业务的状态,也就是我们上边提到的URL和接口状态。
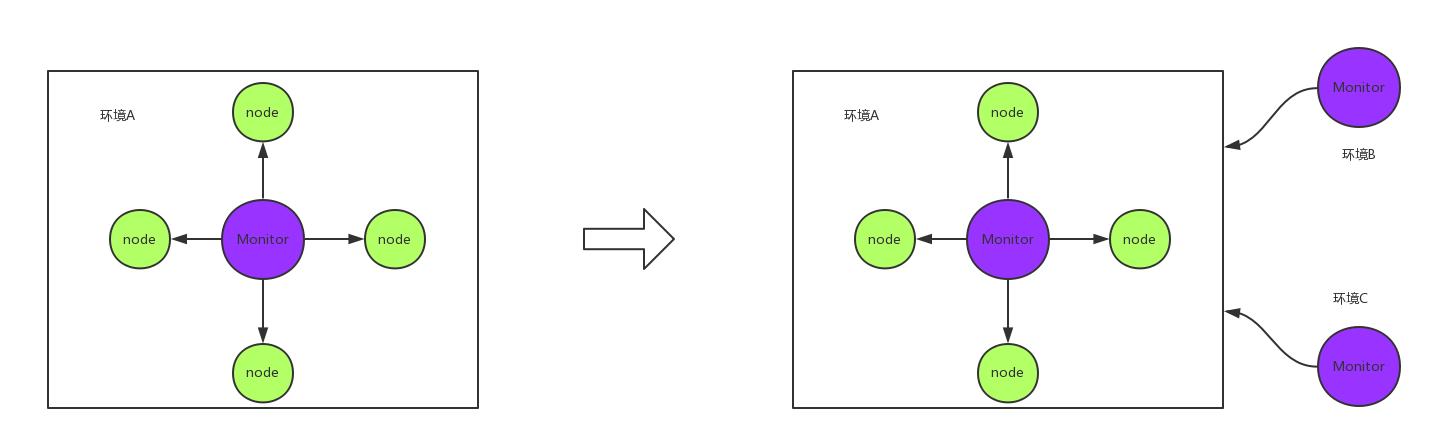
我们能不能直接将监控部署在机房外的环境来节省一套监控呢?例如公司或者其他的机房部署监控。这样不是个好方案,跨网络的监控性能太差了,首先网络之间的延迟都比同机房内要大的多,其次大量监控项频繁的数据传输对带宽也是不小的压力
Nagios监控
我们业务状态监控采用了Nagios,Nagios部署简单配置灵活,这种场景下非常适合。
- 系统环境:Debian8
- nginx + nagios架构
部署Nagios
1.安装基础环境
# apt-get update
# apt-get install -y build-essential libgd2-xpm-dev autoconf gcc libc6 make wget
# apt-get install -y nginx php5-fpm spawn-fcgi fcgiwrap2.下载并解压nagios
# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.0.8.tar.gz
# tar -zxvf nagios-4.0.8.tar.gz
# cd nagios-4.0.8
# ./configure && make all
# make install-groups-users
# usermod -a -G nagios www-data
# make install
# make install-init
# make install-config
# make install-commandmode
# cd ..- nagios安装完成后就可以启动了,但是web页面是无法访问的,查看日志会报错
(No output on stdout) stderr: execvp(/usr/local/nagios/libexec/check_ping, ...) failed. errno is 2: No such file or directory,这是因为我们只安装了nagios的core,没有安装nagios的插件,需要安装插件来支持core工作
3.安装nagios-plugins
# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
# tar -zxvf nagios-plugins-2.2.1.tar.gz
# cd nagios-plugins-2.2.1
# ./configure
# make
# make install
# cd ..- nagios的插件主要是添加了check_ping、checkhttp之类的辅助检查的脚本,默认位于
/usr/local/nagios/libexec/下,可以借助这些插件来监控我们的HTTP接口或主机、服务状态
4.创建nagios web访问的账号密码
# vi /usr/local/bin/htpasswd.pl
#!/usr/bin/perl
use strict;
if ( @ARGV != 2 ){
print "usage: /usr/local/bin/htpasswd.pl <username> <password>\n";
}
else {
print $ARGV[0].":".crypt($ARGV[1],$ARGV[1])."\n";
}
# chmod +x /usr/local/bin/htpasswd.pl
#利用perl脚本生成账号密码到htpasswd.users文件中
# /usr/local/bin/htpasswd.pl nagiosadmin nagios@ops-coffee > /usr/local/nagios/htpasswd.users- nagios默认开启了账号认证,认证相关的配置在这个文件里
/usr/local/nagios/etc/cgi.cfg - 如果安装了httpd服务,可以直接接触htpasswd命令生成密码,这里我们没有httpd服务,所以写个perl脚本来生成密码
5.nginx添加server配置,让浏览器可以访问
server {
listen 80;
server_name ngs.domain.com;
access_log /var/log/nginx/nagios.access.log;
error_log /var/log/nginx/nagios.error.log;
auth_basic "Private";
auth_basic_user_file /usr/local/nagios/htpasswd.users;
root /usr/local/nagios/share;
index index.php index.html;
location / {
try_files $uri $uri/ index.php /nagios;
}
location /nagios {
alias /usr/local/nagios/share;
}
location ~ \.php$ {
include /etc/nginx/fastcgi_params;
fastcgi_pass unix:/var/run/php5-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
location ~ ^/nagios/(.*\.php)$ {
alias /usr/local/nagios/share/$1;
include /etc/nginx/fastcgi_params;
fastcgi_pass unix:/var/run/php5-fpm.sock;
}
location ~ \.cgi$ {
root /usr/local/nagios/sbin/;
rewrite ^/nagios/cgi-bin/(.*)\.cgi /$1.cgi break;
fastcgi_param AUTH_USER $remote_user;
fastcgi_param REMOTE_USER $remote_user;
include /etc/nginx/fastcgi_params;
fastcgi_pass unix:/var/run/fcgiwrap.socket;
}
}6.检查配置文件并启动
#检查配置文件是否有语法错误
# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
#启动nagios服务
# /usr/local/nagios/bin/nagios -d /usr/local/nagios/etc/nagios.cfg
#启动fcgiwrap和php5-fpm服务
# service fcgiwrap restart
# service php5-fpm restart7.浏览器访问服务器IP或域名就可以看到nagios的页面了,默认有本机的监控数据,不需要的话可以在配置文件localhost.cfg中删除
Nagios配置
Nagios的主配置文件路径为/usr/local/nagios/etc/nagios.cfg,里边默认已经配置了一些配置文件的路径,cfg_file=后边配置的都是配置文件,nagios程序会来这里读取配置,我们可以新添加一个专门用来监控HTTP API的配置文件
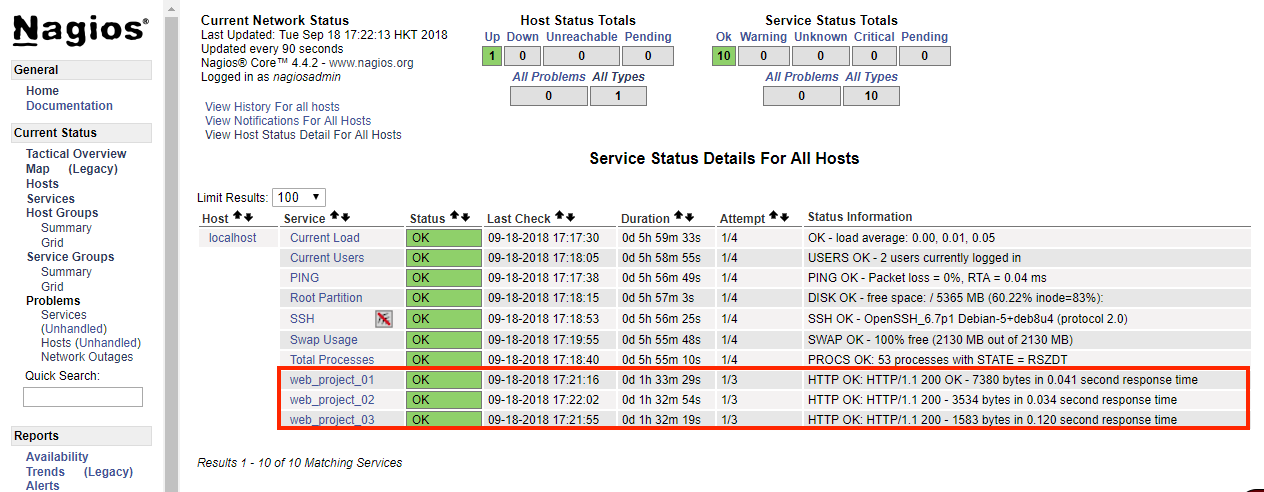
cfg_file=/usr/local/nagios/etc/objects/check_api.cfgcheck_api.cfg里边的内容如下:
define service{
use generic-service
host_name localhost
service_description web_project_01
check_command check_http!ops-coffee.cn -S
}
define service{
use generic-service
host_name localhost
service_description web_project_02
check_command check_http!ops-coffee.cn -S -u / -e 200
}
define service{
use generic-service
host_name localhost
service_description web_project_03
check_command check_http!ops-coffee.cn -S -u /action/health -k "sign:e5dhn"
}- define service:定义一个服务,每一个页面或api属于一个服务
- use:定义服务使用的模板,模板配置文件在
/usr/local/nagios/etc/objects/templates.cfg - host_name:定义服务所属的主机,我们这里区别主机意义不大,统一都属于localhost好了
- service_description:定义服务描述,这个值会最终展示在web页面上的service字段,定义应简单有意义
- check_command:定义服务检查使用的命令,命令的配置文件在
/usr/local/nagios/etc/objects/commands.cfg - check_http检测https接口时可以使用-S参数,如果报错
SSL is not available,那么你需要先安装libssl-dev包,然后重新编译(./configure --with-openssl=/usr/bin/openssl)部署nagios-plugin插件添加对ssl的支持
check_command我们配置了check_http,需要修改commands.cfg文件中默认的check_http配置如下:
define command {
command_name check_http
command_line $USER1$/check_http -H $ARG1$
}- define command:定义一个command
- command_name:定义command的名字,在主机或服务的配置文件中可以引用
- command_line:定义命令的路径和执行方式,这个
check_http就是我们通过安装nagios-plugin生成的,位于/usr/local/nagios/libexec/下,check_http的详细用法可以通过check_http -h查看,支持比较广泛
use我们配置了generic-service,可以通过配置服务模板定义很多默认的配置如下:
define service {
name generic-service ; The 'name' of this service template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized (disabling this can lead to major performance problems)
obsess_over_service 1 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
is_volatile 0 ; The service is not volatile
check_period 24x7 ; The service can be checked at any time of the day
max_check_attempts 2 ; Re-check the service up to 3 times in order to determine its final (hard) state
check_interval 1 ; Check the service every 10 minutes under normal conditions
retry_interval 1 ; Re-check the service every two minutes until a hard state can be determined
contact_groups admins ; Notifications get sent out to everyone in the 'admins' group
notification_options w,u,c,r ; Send notifications about warning, unknown, critical, and recovery events
notification_interval 60 ; Re-notify about service problems every hour
notification_period 24x7 ; Notifications can be sent out at any time
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL SERVICE, JUST A TEMPLATE!
}配置太多就不一一解释了,配合后边的英文注释应该看得懂,说几个重要的
- max_check_attempts:重试几次来最终确定服务的状态,例如我们一个服务挂了,需要重试3次才会确定这个服务确实是挂了,然后发邮件或短信通知我们
- check_interval:检查频率配置,在服务正常的情况下多长时间轮训检查一次,这里为了更及时的反馈结果我们配置一分钟一次
- retry_interval:当服务状态发生变更的时候多长时间轮序检查一次,我们也给配置一分钟一次
- contact_groups:定义联系人组,当发生故障需要报警时,发送报警给哪个组,这个组的配置文件在
/usr/local/nagios/etc/objects/contacts.cfg
contact_groups我们配置了admins,接下来看下contacts.cfg的配置
define contact{
contact_name sa ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,u,r
host_notification_commands notify-host-by-email,notify-host-by-sms
service_notification_commands notify-service-by-email,notify-service-by-sms
email [email protected]
pager 15821212121,15822222222
}
define contactgroup{
contactgroup_name admins
alias Nagios Administrators
members sa
}- contactgroup就是我们定义的联系人组admins
- admins组管理了成员sa联系人
- sa联系人定义了主机和服务的命令,例如这里我们定义的notify-host-by-email,notify-host-by-sms发邮件和发短信的命令,这个命令的定义位置跟我们check_http的定义都在文件
/usr/local/nagios/etc/objects/commands.cfg文件内
全部配置完成后重启nagios服务,会看到监控已经正常
Nagstamon插件
介绍一款配合nagios用起来非常棒的插件Nagstamon,Nagstamon是一款nagios的桌面小工具(实际上现在不仅仅能配合nagios使用,还能配合zabbix等使用),启动后常驻系统托盘,当nagios监控状态发生变化时会及时的跳出来并发出声音警告,能够更加及时的获取业务状态。
配置如下:
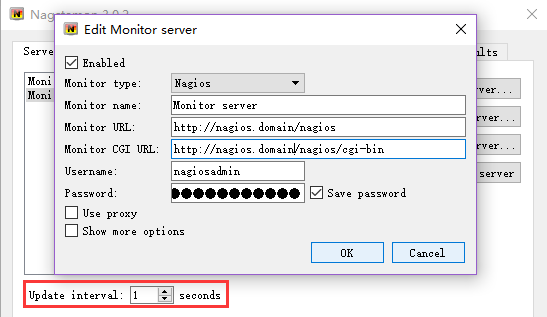
- Update interval能够配置多长时间取一次nagios的状态,我们这里调整为1s
- 当出现报警时桌面直接飙红,给你心跳加速的感觉

写在最后
- 业务状态监控作为Zabbix之类过程监控的补充,并不能替代过程监控系统,在我们过程监控不是很完善的情况下很有用,目前我们有相当一部分的报警都首先发现于这套业务状态监控
- 选择Nagios主要是她比较纯粹,专注状态监控(有插件实现过程记录),且对Nagios比较熟悉了。Nagios看似配置复杂,几个配置文件环环相扣,实际上理清楚配置文件之间的关系就会发现配置合理且简单
- 部署的状态监控节点越多覆盖地区越多用户状态获取就越准确,但由于网络环境复杂,我们也不可能在每个省市、节点部署监控系统来监控项目的状态,如有必要可以考虑一些商业监控方案,能够做到全球节点监控,但相应的成本可能就会增加,要综合权衡
