简洁表单替代复杂JSON,配置直观又简单
昨天晚上给微信群里的朋友们分享了任务系统,包括系统介绍、设计理念以及使用场景等等相关的话题,其中就有朋友对任务参数这个功能提出了异议,通过JSON数据格式来定义任务参数,配置麻烦,不好理解,使用成本高。实际上关于JSON定义任务参数这个功能一早就有优化的想法,但一直没下定决心去做,主要是目前大伙已经使用习惯,并没有出现什么问题或者实现不了的场景,所以优化动力不大,这次既然又有朋友提起,那就花点时间优化一下吧。本身并不复杂,几个小时的时间从设计到编码再到上线,最后更新原始数据并通过测试验收,没有问题
任务参数
任务系统可以像乐高搭积木一样组合不同的子任务为一个模板,然后基于模板配合参数来创建任务流并执行,以此来满足各种各样的日常运维场景,十分灵活。那任务参数在这个任务流执行过程中有什么用?我们就用一个简单的例子来解释下,假如有一个项目构建并部署的任务流,只有四个步骤:拉代码、编译、打包和更新,拉代码就是去git仓库拉代码,编译就是将源代码编译成可执行的二进制文件,打包就是将可执行的二进制文件打包成docker镜像,更新则是将docker镜像更新到对应的环境里去
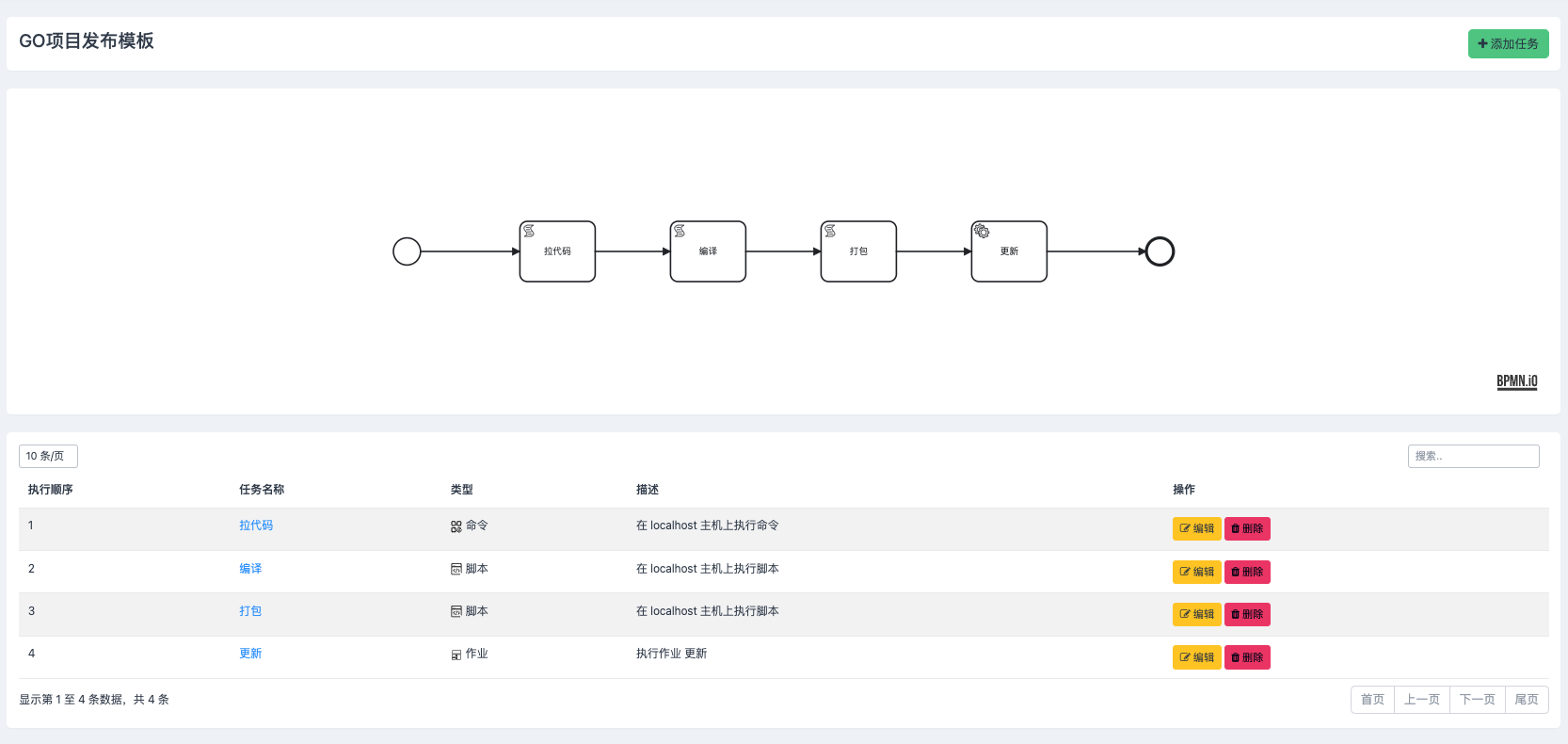
这个任务流需要用到三个参数:branch、version和environment,其中branch用来定义git的分支,需要用户在任务执行时填写,version用来定义构建完的版本号,来自于构建子任务的执行结果,environment用来定义本次部署的环境,需要用户在任务执行时选择。其中除了version来自于其他子任务的结果外,branch和environment都需要用户自己在任务执行时提交,类似这样
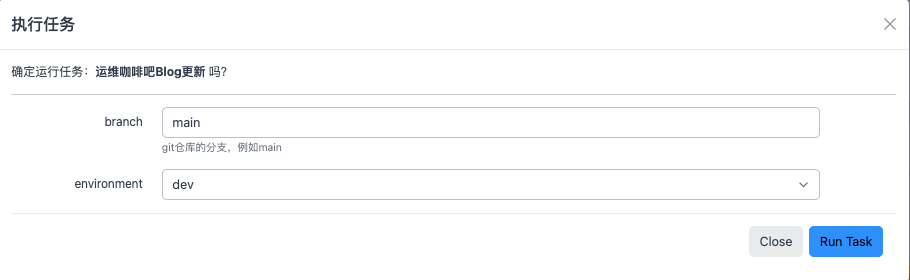
branch、version和environment这三个参数就是任务参数,任务在执行的过程中需要用到这三个参数对应的结果值。关于version参数的获取上篇文章任务系统之结果传递有过详细的介绍,这里不赘述。那另外两个参数branch和environment就需要我们在任务中定义,在任务执行时传递
任务执行时传递的参数每个任务都不一样,需要根据任务本身来配置,不仅要能配置任务需要传递的参数,同时也要配置参数渲染的样式,例如有些参数需要渲染成input输入框让用户填写,有些参数需要渲染成select下拉框让用户选择,有些参数有默认值,而有些参数则需要显示帮助信息,主打灵活
JSON数据
为了满足这个需求,我们最早采用了JSON数据格式来定义这些参数,其中有三个保留的KEY:_helper、_default和_select,分别定义帮助信息、默认值和下拉框选项,而其他非保留的KEY则作为任务参数存在。格式大概这样
{
"branch": "",
"environment": "",
"_select": {
"environment": {
"dev": "dev",
"test": "test",
"prod": "prod",
"required": "------请选择更新环境------"
}
},
"_helper": {
"branch": "git仓库的分支,例如main"
},
"_default": {
"branch": "main"
}
}这里定义了两个参数branch和environment,其中branch在_helper中定义了帮助信息,在_default中定义了默认值,而environment则通过_select定义为了选择值,选项包含dev、test和prod,required则表示默认选择为空
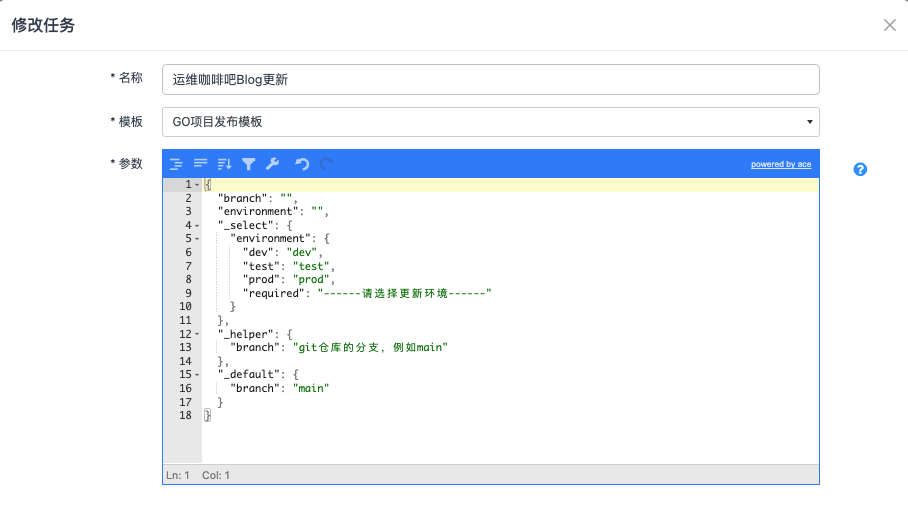
然后前端通过解析这个JSON数据生成Form表单,以让用户填写或选择参数的值,从而在提交时传递给后端程序继续处理,虽然略微粗糙,但功能实现也没有问题
拟图形化
通过直接编辑JSON数据来实现参数定义虽然功能没有问题,但是使用起来却并不友好,要先了解JSON的数据格式,以及那几个默认保留的KEY,有一定的使用成本,并且JSON格式的定义也是当时拍脑袋决定的,并不优雅。所以要优化成一种更友好的定义方式,最好不要学习或尽量少的学习
首先在数据结构上,改变了之前纯KV的数据结构,改为列表包含字典的形式,就像这样:
[
{
"name": "branch",
"type": "string",
"value": "main",
"helper": "git仓库的分支,例如main"
},
{
"name": "environment",
"type": "list",
"value": "dev,test,prod",
"helper": ""
}
],列表里包含字典,每个字典一个参数,字典里定义参数的类型、默认值和帮助信息,简洁且清晰。然后渲染成表格的方式给用户填写
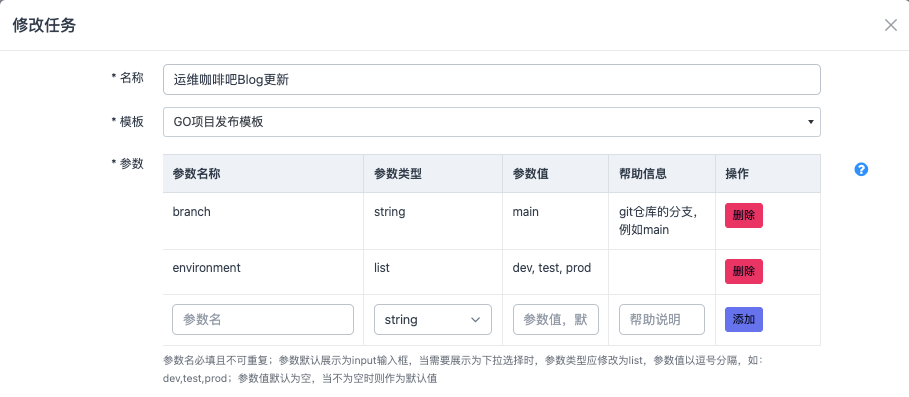
这样看上去是不是就简单多了,不需要了解JSON,不需要保留参数,只需要填写个表单即可,直观又简单。从JSON定义到填写表单,同事说就像从命令行改成了图形化,这描述很形象
更新流程
涉及到数据结构的变更,那线上更新就不仅仅是拉代码这么简单了,代码更新要配合数据结构的变更,为此专门写了个数据结构变更脚本
from ops.coffee.models import Task
def update_kwargs_format():
for task in Task.objects.all():
if isinstance(task.kwargs, dict):
select = task.kwargs.get('_select', {})
helper = task.kwargs.get('_helper', {})
default = task.kwargs.get('_default', {})
new_kwargs = []
for k, v in task.kwargs.items():
if k not in ['_select', '_helper', '_default']:
_type = 'list' if k in select.keys() else 'string'
if v:
_value = v
elif k in default.keys():
_value = default[k]
elif k in select.keys():
_keys = list(select[k].keys())
if 'required' in _keys:
_keys.remove('required')
_keys = ['required'] + _keys
_value = ','.join(_keys)
else:
_value = ''
if k in helper.keys():
_helper = helper[k]
elif k in select.keys():
_helper = select[k].get('required', '')
else:
_helper = ''
new_kwargs.append({
'name': k,
'type': _type,
'value': _value,
'helper': _helper
})
task.kwargs = new_kwargs
task.save()
else:
print('==>taskID: {}, taskName: {}, taskArgs: {}'.format(task.id, task.name, task.kwargs))线上更新流程就先通知大伙更新,然后停掉Celery任务进程防止任务执行,拉代码、运行数据结构变更脚本、启动Celery任务进程,最后线上测试验证
一切OK,十分顺利
