任务系统之结果传递
任务系统可以像乐高搭积木一样组合不同的子任务为一个模板,然后基于模板配合参数来创建任务流并执行,以此来满足各种各样的日常运维场景,例如项目打包、持续集成&部署、数据备份、定时巡检、漏洞修复等等,十分的好用
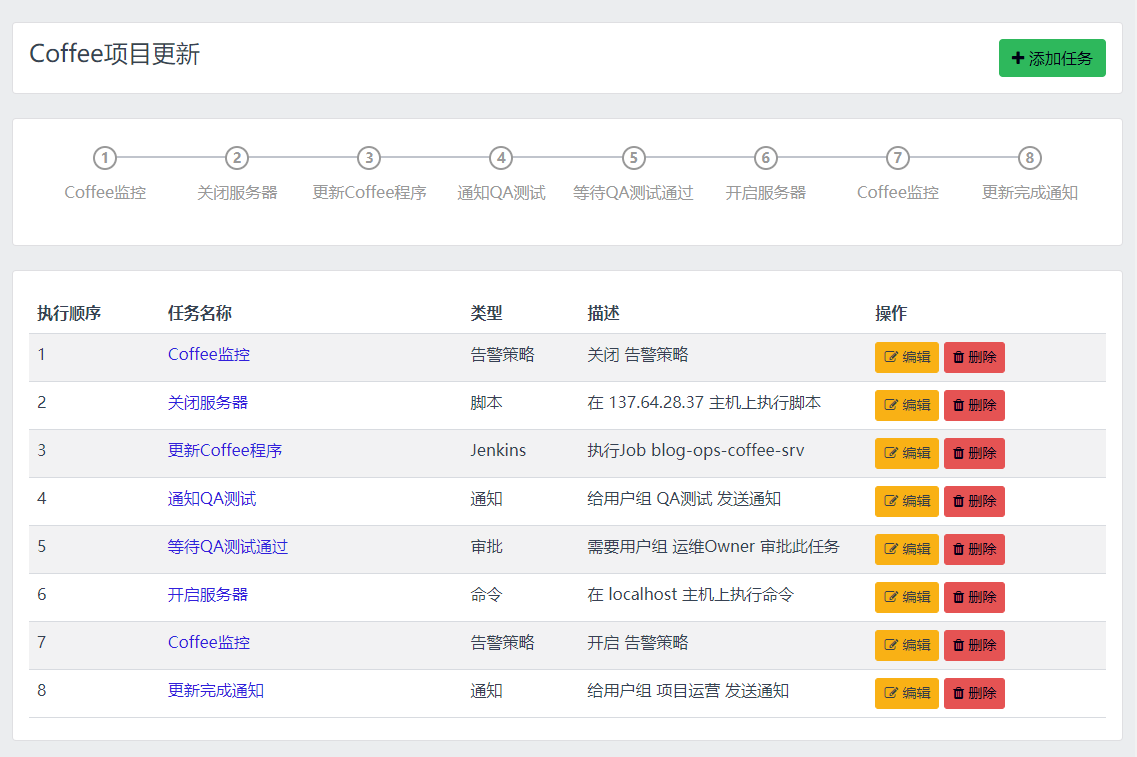
任务系统支持的子任务类型非常丰富,例如命令、脚本、Ansible作业、JenkinsJob甚至是审批、通知等等。这些子任务在保持相对独立的同时,也会有一定的数据交互需求,例如一个项目发布的任务流中会包含打包和更新两个步骤,需要将打包执行步骤执行完成后生成的版本号传递给更新步骤去使用,诸如类似的情况,都需要用到结果数据的传递。也就是将当前子任务的执行结果,作为后续子任务的参数去使用,实现子任务结果数据的传递,从而完成子任务之间的数据交互
想一下,这个功能该如何实现呢?
参数定义
首先是参数定义,还以上边的项目发布任务流中的打包为例,打包步骤执行完成后需要提取出来版本号数据,如果打包程序是python脚本,那可以通过获取python最终return出来的数据,那如果打包程序是个shell脚本呢?shell脚本无法return数据,这种情况下就需要找到一种相对通用的方法来准确获取数据,并完成最终的结果参数定义
我们采用的方式是解析标准输出stdout的结果,无论是哪种类型的子任务都会有标准输出,如果想要定义结果参数给后续步骤使用,只需要按照固定的格式输出到标准输出即可,例如,我们定义所有符合这样到格式都是结果参数:[[ var_name::var_value ]],双中括号包括,参数名和参数值之间用双冒号分割
例如shell脚本中可以这样用:
echo [[ name::运维咖啡吧 ]]python脚本中则可以这样用:
print('[[ site::blog.ops-coffee.cn ]]')这样我们可以在子任务执行完成后通过解析标准输出stdout从而获取到这个步骤所定义的可以给后续步骤使用的变量
def stdout_args(text: str):
# 返回结果为: {'key1': 'value1', 'key2': 'value2'}
pattern = r'\[\[([^:]+)::([^]]+)\]\]'
matches = re.findall(pattern, text)
return {key.strip(): value.strip() for key, value in matches}
stdout_args('标准输出的内容')参数使用
参数定义完成了,再来聊聊如何使用,就是将子任务执行结果解析出来的参数,应用到其他需要用到的地方,例如用到脚本类型子任务的脚本里,或者是API类型子任务的Header中,再或者是通知类型子任务的通知内容中,所有可能用得到的地方都可以用
这里我们采用了Jinja模板渲染的方式,所有想要使用参数的地方都使用{{ var_name }}来填充,例如:
hello {{ name }}
欢迎访问我的博客 {{ site }}这样我们只需要通过Jinja模板渲染就能完成参数名称和参数值的替换。不仅能够实现参数替换,同时还能利用JinJa模板的高级语法,做些判断循环之类的内容,使用更加灵活和强大
def template_render(template_string, kwargs):
env = Environment(loader=BaseLoader())
template = env.from_string(template_string)
return template.render(kwargs)所有包含参数定义的地方都当作Jinja的模板传入template_render函数,获取渲染后的结果
参数传递
上边解决了参数定义的参数使用的问题,那还有最后一个问题要解决,就是参数传递,在调用template_render函数进行渲染时需要两个参数,template_string是所有需要替换参数的内容,例如脚本、通知等等内容。而另一个参数kwargs则是一个完整的参数字典,包含系统默认参数、任务执行时传递的参数以及当前子任务之前已经执行的所有子任务的结果参数
在执行每个子任务之前都会先获取到完整的参数字典,然后再在有参数定义的地方调用template_render完成参数替换,最后再进行正常的子任务执行
至此实现了从结果参数定义到结果参数使用到完整流程
其他问题
由于每一个子任务都能定义结果参数,如果结果参数重复了该怎么办?例如一个任务流有A、B、C三个子任务,其中A、B两个子任务的结果参数中都有name,而子任务C恰好要用到结果参数name,那么究竟应该用A的name还是用B的name,这就需要解决冲突问题,通常三种方法,第一种是覆盖,B结果覆盖A,第二种是忽略,B判断如果已经存在同名参数则直接忽略,第三种则是都保存,根据子任务加以区分:{'taskA': 'A', 'taskB': 'B'},然后在使用时主动选择用哪个
或者是规定所有子任务都不允许定义重复的参数名,而这个对于我们来说不太好,任务系统高度自由,所有的子任务都可以用户自定义,用户行为很难限制,最好通过技术的手段来解决,同时对于API类型的子任务来说,API返回的结果一般是没有办法左右的,所以规定并不适用
那究竟该如何解决,如果场景简单的话就定义好规则,无论是覆盖还是忽略都可,任务系统按照提前定义好的覆盖或忽略规则来处理即可,但很明显对于高度自由的任务系统是不合适的,最终我们选择了都记录,每一个子任务运行完成之后他的结果参数都单独记录,在需要构建完整字典参数时加上子任务的标识:SUBTASK_子任务ID_RESULT
results = {
'SUBTASK_{}_RESULT'.format(i.temptask.subtask.id): (i.results or {}) for i in
tasklog.subtask_logs.filter(sortnum__lt=subtask_log.sortnum)
}相应的在使用结果参数时,加上子任务标识即可
hello {{ SUBTASK_37_RESULT.name }}至此问题完美解决
写在最后
能通过技术手段限制的,最好通过技术手段来限制,而非规则或制度
实现结果参数的传递非常重要,能让任务系统更加的灵活和强大,尤其是与API类型子任务相结合,低代码,实现各种复杂的场景,例如我们现在唯一还在使用的第三方运维系统JumpServer的自动化管理,用户所属项目改变自动给JumpServer下相应的资源授权、用户离职自动禁用JumpServer用户等等
