多云系统之资源同步过程解析
多云系统主要是用来统一多云资源实现集中管理,同时基于关联关系来构建资源拓扑,为上层业务提供清晰准确的基础数据。到目前为止已接入国内外十多个主要云厂商下数十种云资源,构建了完整的本地资源数据库。前边写过三篇文章分别介绍了多云系统的三个核心功能:多云配置、资源管理和关系管理。微信群里有小伙伴想要更深入的了解下资源同步的处理逻辑,于是便有了这篇文章,记录下我是如何实现多云环境下的资源同步的
整体逻辑如下:新建云帐号-->触发Signals自动创建周期任务-->周期任务定时触发同步任务sync_resources执行-->sync_resources会循环云帐号下要同步的资源然后调用sync_resource方法逐个资源类型同步-->sync_resource方法调用sync方法同步资源-->sync方法根据传入的资源类型调用不同的资源同步方法-->资源同步方法进行资源同步的操作同时记录同步过程日志
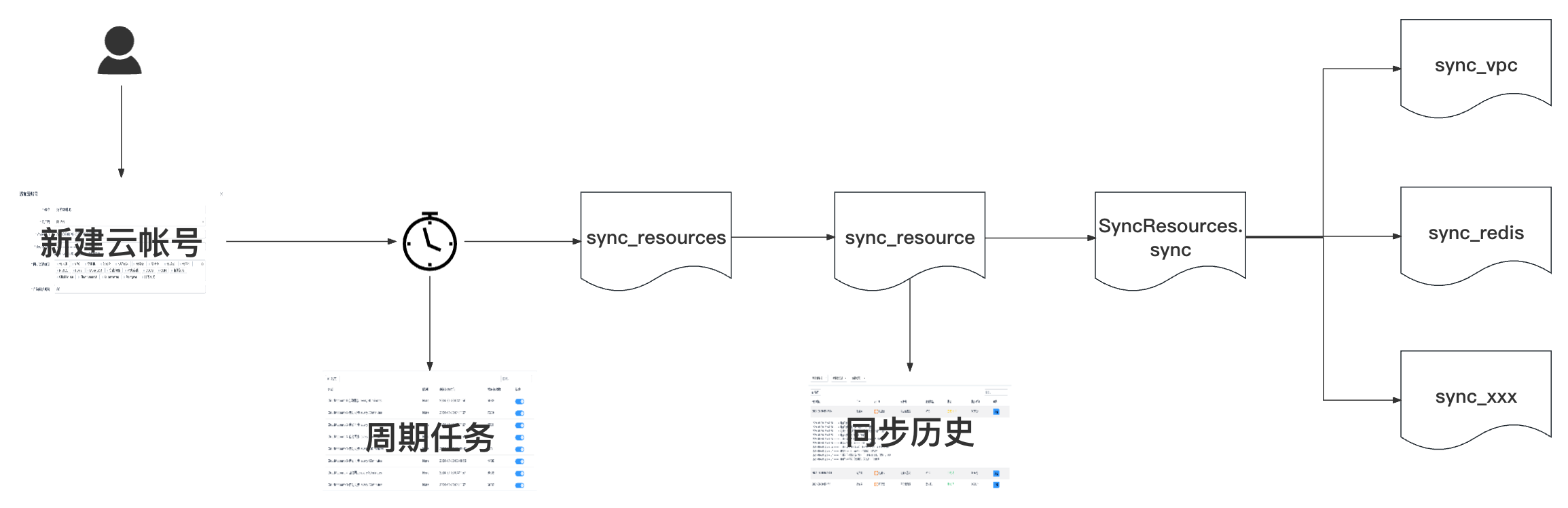
接下来具体看下每一步都做了啥,为了让大家有更清晰的理解,会以伪代码的方式呈现
新建云帐号,这一步的主要功能就是接收用户输入的云帐号相关数据,然后插入数据库。云帐号相关数据就包括名称、厂商、AccessID、SecretKey以及同步资源类型和同步时间间隔等,所有的信息为验证账号和同步资源而服务
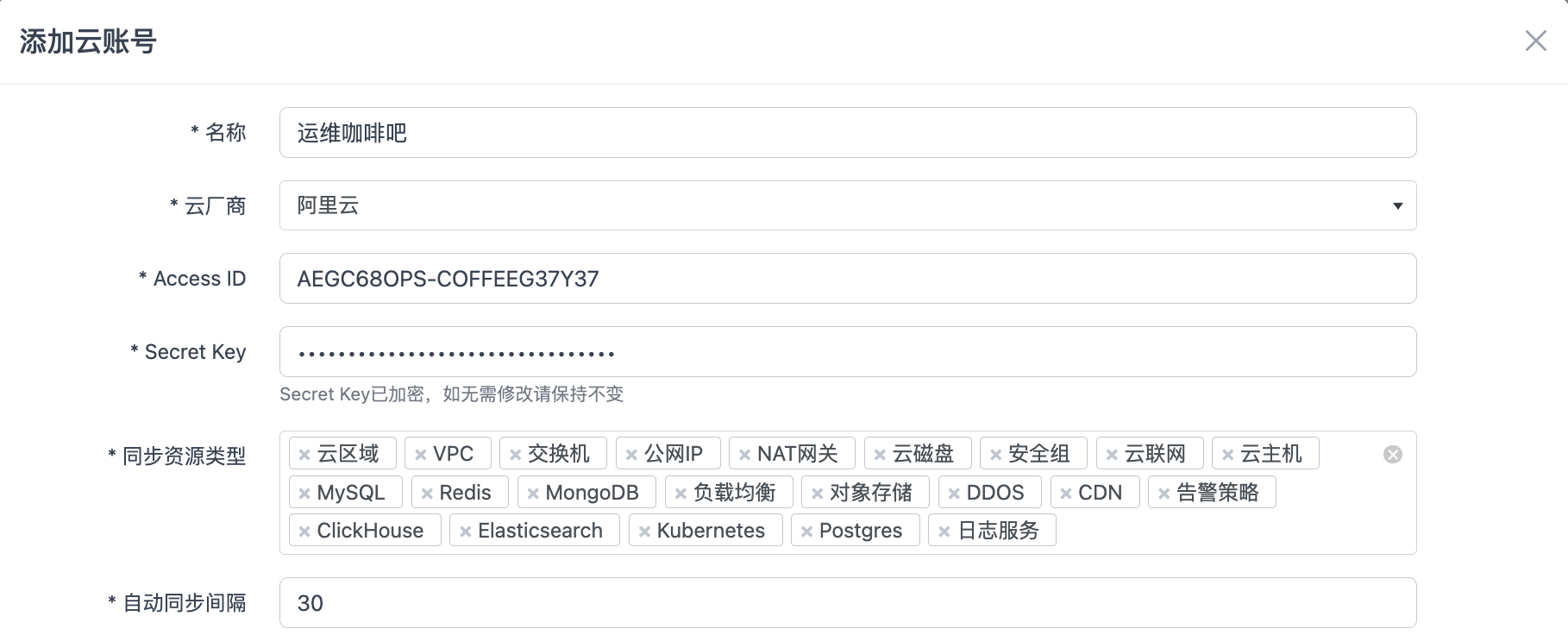
当云帐号数据保存后就会触发post_save的signal,这个signal会自动创建一条资源同步的周期性任务
@receiver(signals.post_save, sender=CloudAccount)
def cloud_account_post(instance, created, **kwargs):
"""云资源自动同步函数"""
with transaction.atomic():
_c, created = IntervalSchedule.objects.get_or_create(
every=instance.interval,
period=IntervalSchedule.MINUTES,
)
_p = PeriodicTask.objects.update_or_create(
name='CloudAccount-{}-自动同步'.format(instance.id),
defaults={
"task": 'carrier.tasks.sync_resources',
"args": [1, int(instance.id)],
"enabled": 1 if int(instance.interval) else 0,
"interval": _c
}
)若想临时关闭同步任务的话可以将自动同步间隔改为0,或者在队列状态页面上选择相应的任务关闭同步,同时在队列状态页面还能查看所有的计划任务以及Celery下Worker的状态,这个我上篇文章监控Celery不一定非要使用Flower有专程的讲过
Signals创建的周期任务会根据设置的自动同步时间间隔周期调用sync_resources方法,sync_resources方法接收两个参数用户以及云帐号的主键ID,根据主键找到对应的云帐号,循环云帐号下配置的同步资源类型然后调用sync_resource方法
def sync_resources(user, pk):
try:
instance = CloudAccount.objects.get(id=pk)
except CloudAccount.DoesNotExist:
return True, '当前要同步的云账号不存在,id:%d' % pk
for resource in instance.resource.all():
sync_resource.delay(user, pk, resource.id)
return Truesync_resource方法接收用户、云帐号的主键ID以及云资源类型ID三个参数,根据云帐号的主键ID确定要同步的云帐号,根据资源类型ID确定要同步的资源类型,向CloudSyncLog表写入一条数据作为同步日志,同时初始化同步记录状态为进行中Running,调用SyncResources().sync()进行具体的资源同步,通过CloudSyncLogger来记录同步过程的详情
def sync_resource(user, pk, resource_id):
try:
instance = CloudAccount.objects.get(id=pk)
except CloudAccount.DoesNotExist:
return True, '当前要同步的云账号不存在,id:%d' % pk
resource = Resource.objects.get(id=resource_id)
# 添加同步日志
_t = CloudSyncLog.objects.create(
create_user_id=user,
cloud_account=instance,
resource_type=resource,
state='Running'
)
CloudSyncLogger(_t.id).add('开始同步 {} \n'.format(resource.name))
success, data = SyncResources(_t.id).sync(resource.id)
CloudSyncLogger(_t.id, 1 if success else 0).add(data + '\n')
return True, '{} 同步 {}'.format(resource.name, '成功' if success else '失败')这里之所以会将sync_resources和sync_resource方法分开,主要是sync_resources方法只能一次全部同步云帐号下所有配置同步的资源,而在某些情况下用户需要单独同步某个账号下的某个资源类型,例如我们在修改了云上资源后希望立刻看到资源的属性变化,此时需要手动同步某个账号下的某个资源
SyncResources().sync()方法接收资源类型ID,然后根据资源类型ID调用具体类型的资源同步方法执行同步,例如要同步资源ID为5的VPC资源,则调用sync_vpc方法,例如要同步资源ID为15的Redis资源,则调用sync_redis方法
class SyncResources:
def __init__(self, tid: int):
self.tid = tid
self.sync_log = CloudSyncLog.objects.get(id=self.tid)
self.cloud_account = self.sync_log.cloud_account
def sync(self, resource_type: int):
_map = {
5: self.sync_vpc,
15: self.sync_redis,
}
if resource_type in _map:
state, message = _map[resource_type]()
# 设置长时间未更新资源过期
if state:
set_expired(resource_type)
else:
return False, '暂不支持当前资源类型的数据同步'
return state, message对于云上已经删除的资源,同步时可能并不会更新资源属性及状态,所以在资源同步完成后,需要判断下资源的同步状态,若资源同步成功则调用方法set_expired来修改长时间未更新的资源状态为已过期,保证本地资源状态准确,当然根据你的需要也可以通过set_expired方法直接删除长时间未更新的资源
而对于资源同步方法sync_vpc,会循环所有Region,然后获取Region下的所有数据,通过update_or_create方法来新建或者修改资源数据,在这个过程中不断的记录同步过程日志,一个简单的示例如下
def sync_vpc(self):
total_regions = region_total_instances = total_instances = 0
for region in self.cloud_account.cloud.cloudregion_set.all():
if self.cloud_account.cloud.name == '阿里云':
CloudSyncLogger(self.tid).add('开始同步可用区 {} 下的资源\n'.format(region))
total_regions += 1
state, code, data = AlibabaCloudVpcApi(
self.access_id, self.access_key, region.code
).describe_vpcs()
for instance in data['Vpcs']['Vpc']:
_instance, created = Vpc.objects.update_or_create(
defaults=format_a_vpc_data(instance),
**{'cloud': self.cloud_account.cloud,
'cloud_account': self.cloud_account,
'cloud_region': region,
'instance_id': instance['VpcId']}
)
# 同步完成计数器加1
region_total_instances += 1
total_instances += 1
# 当一个可用区循环结束,则记录当前可用区数据
CloudSyncLogger(self.tid).add('可用区 {} 下一共有 {} 实例,已同步 {} 实例\n'.format(
region, data['TotalCount'], region_total_instances))
# 同时将可用区下的主机数量置为0
region_total_instances = 0
if self.cloud_account.cloud.name == '腾讯云':
pass
if self.cloud_account.cloud.name == '华为云':
pass
if self.cloud_account.cloud.name == 'Ucloud':
pass
return True, '本次一共同步了 {} 个区域下的 {} 个实例'.format(total_regions, total_instances)所有资源的所有同步过程都可以通过详细的日志记录来查看,当然因为同步日志也记录了云厂商、资源类型和同步状态,也可以根据这些维度来过滤查看具体厂商具体资源具体状态的同步情况

至此,整个资源同步的逻辑就相对完善了
