运维效率之数据迁移自动化
overmind系统上线三个月,累计执行任务800+,自动审核执行SQL超过5000条,效率提升相当明显,离“一杯咖啡,轻松运维”的目标又进了一步。
自吹自擂
起初在写overmind时就有考虑到之后的扩展,不仅仅是作为SQL自动审核执行的平台,更希望能将其打造成一个数据库自动化运维的专业系统,SQL自动审核执行作为第一个功能被开发了出来。三个月的使用后overmind得到了大家的认可,并且切切实实帮助我们节约了时间,这也给予了我这个非专业开发、半吊子DBA莫大的鼓励和信心。
日常工作中经常会接到把数据库整库或单表从生产环境导入到测试环境或测试A导入到测试B等数据库、表之间的数据互导需求,这类操作没有太高技术含量还费时费力容易出错,最适合做到自动化的流程中,这便是overmind要实现的第二个功能:工单+自动化数据迁移。
为什么需要工单?目前的流程都是通过邮件的方式,需求邮件到DBA,DBA执行导数据的操作。自动化的流程理论来说应该从头至尾都无需人工参与,但涉及到数据安全问题,还是需要DBA确认,所以加了工单。同时工单具有状态自助追踪,减少沟通成本等优点,后续也方便统计工单量等指标,以便优化服务与流程。同时为了能够保证工单及时被处理,我们每一步都会增加邮件和IM的通知,给用户最及时的反馈。
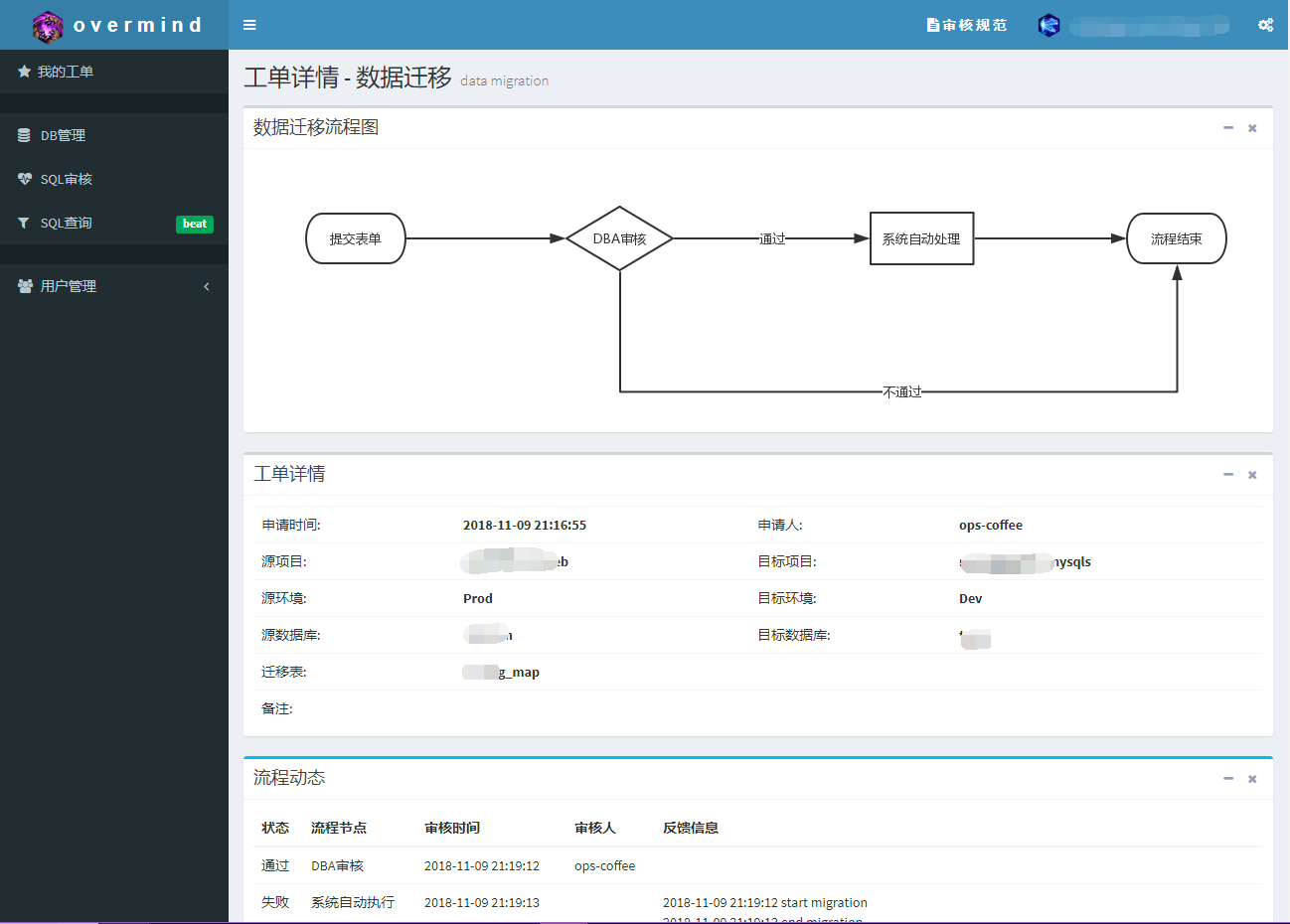
数据迁移的工单流程很简单,用户提交工单,DBA进行审核,审核通过系统自动执行迁移操作,审核不通过流程结束。流程图图如下:
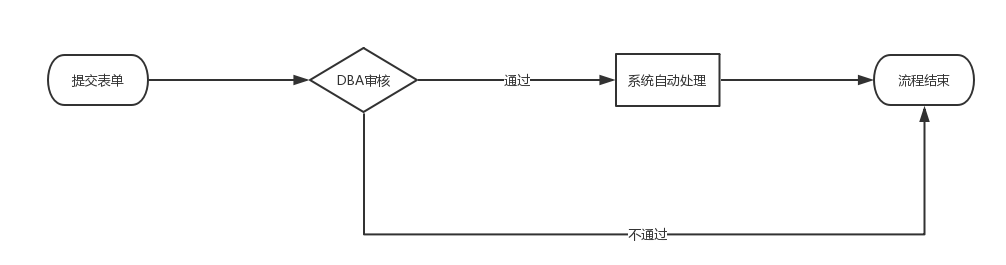
流程中没有加入项目leader等的多层审核方式,主要是因为
- 尽量跟之前的邮件流程保持一致,避免给用户制造麻烦
- 团队规模较小,数据敏感度DBA基本可以把控,同时会在通知邮件中加上相关的同事以知晓
迁移功能
数据库迁移主要是利用mysql的导入导出功能,核心的命令就一个
mysqldump -h 10.82.9.19 -P 3306 -uops -pcoffee --default-character-set=utf8 --single-transaction --databases dbname | mysql -h 192.168.106.91 -P 3306 -uops -pcoffee --default-character-set=utf8 dbname以上命令是shell命令,在python下没有找到直接导入导出mysql数据的包,只能在python代码中调用shell命令,推荐使用subprocess模块,这个模块有着更加丰富的使用方法,方便获取最终的命令执行状态和输出结果,转换成完整的python类如下:
from subprocess import Popen, PIPE
class Cmd():
def __init__(self):
self.src_host = '10.82.9.19'
self.src_port = 3306
self.src_database = 'dbname'
self.des_host = '192.168.106.91'
self.des_port = 3306
self.des_database = 'dbname'
self.tables = 'all'
self.username = 'ops'
self.password = 'coffee'
def migration(self):
# 利用mysqldump命令备份
dump = "mysqldump -h %s -P %d -u%s -p%s --default-character-set=utf8 --single-transaction --databases %s" % (
self.src_host, self.src_port, self.username, self.password, self.src_database
)
# 如果是对表的导出则加上表名,是个字符串'table1 table2 table3'
if self.tables != 'all':
dump += ' --tables %s' % self.tables
# 利用mysql命令导入
mysql = "mysql -h %s -P %d -u%s -p%s --default-character-set=utf8 %s" % (
self.des_host, self.des_port, self.username, self.password, self.des_database
)
# 执行导出导入shell命令
process = Popen("%s | %s" % (dump, mysql), stderr=PIPE, shell=True)
process_stdout = process.communicate()
# 判断shell命令执行结果状态
if (process.returncode == 0):
print('迁移成功!')
else:
print(process_stdout[1].decode('utf8').strip())
Cmd().migration()这里采用了shell中的管道,管道用|符号分割两个命令,管道符前的命令正确输出作为管道符后命令的输入,好处是不需要生成单独的sql文件存放在磁盘上,也就不需要考虑文件删除,占用磁盘的问题,缺点是导出大的数据库时可能会造成OOM,这个要根据自身情况综合权衡。
导数据属于耗时操作,在web中应异步执行,这里采用了Celery来处理,这篇文章Django配置Celery执行异步任务和定时任务有详细介绍Django中Celery的使用
系统界面
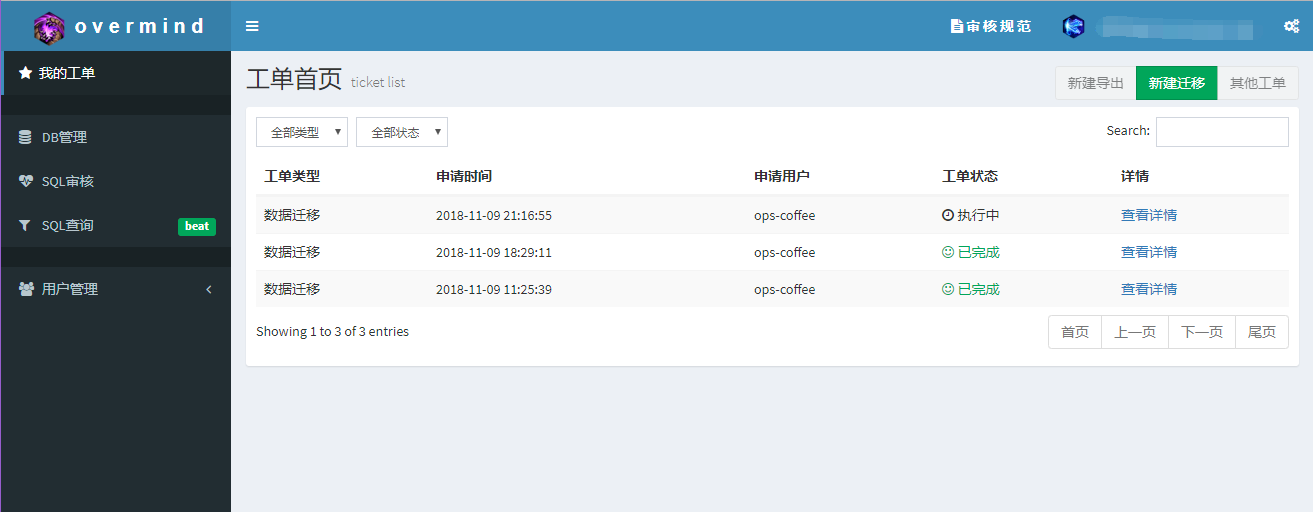
工单列表页:普通用户只显示自己提交的工单,工单状态一目了然,还有实用的搜索功能
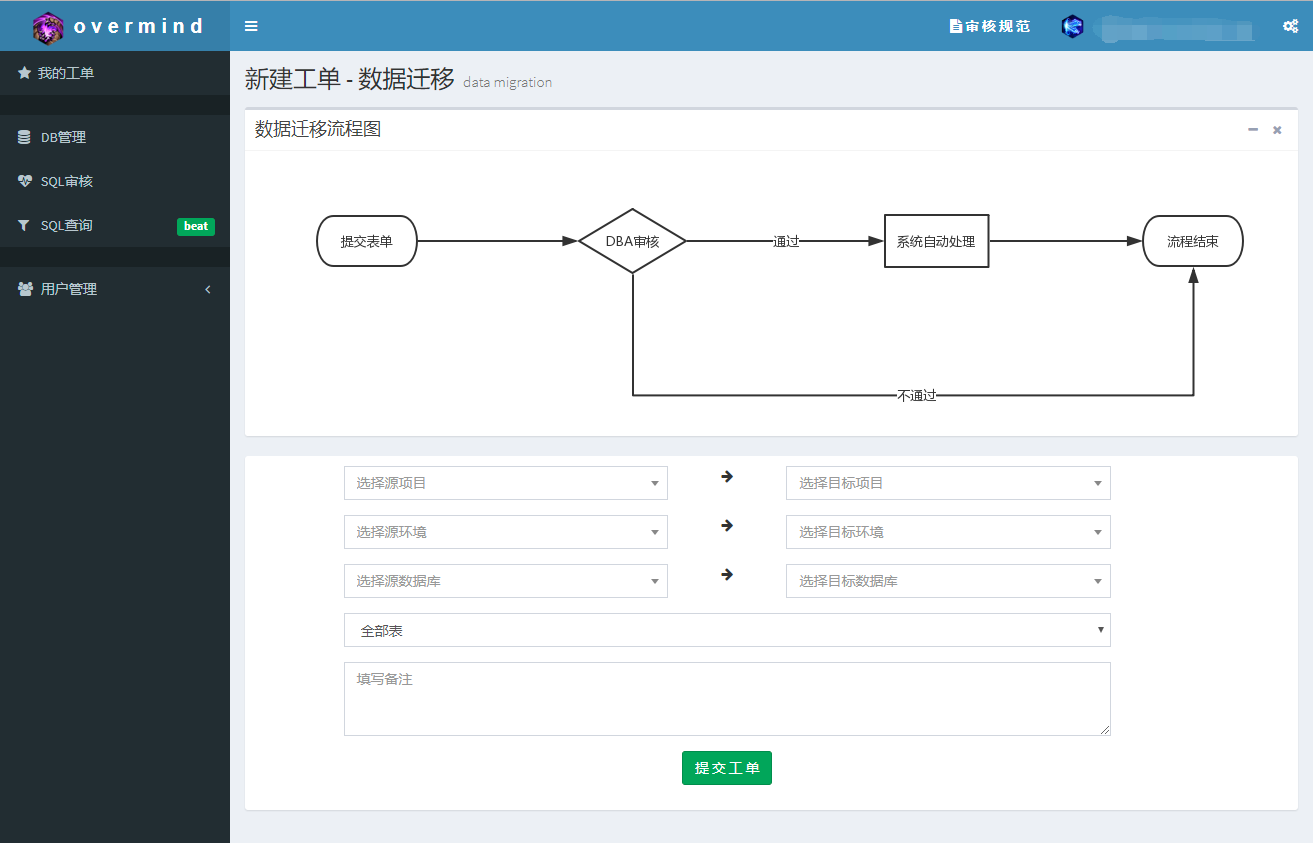
提交工单页:overmind维护了一份数据库列表,供系统里所有的功能使用,这里也不例外
工单审核页:审核页和详情页其实是同一个页面,只是根据工单不同的状态展示不同的元素
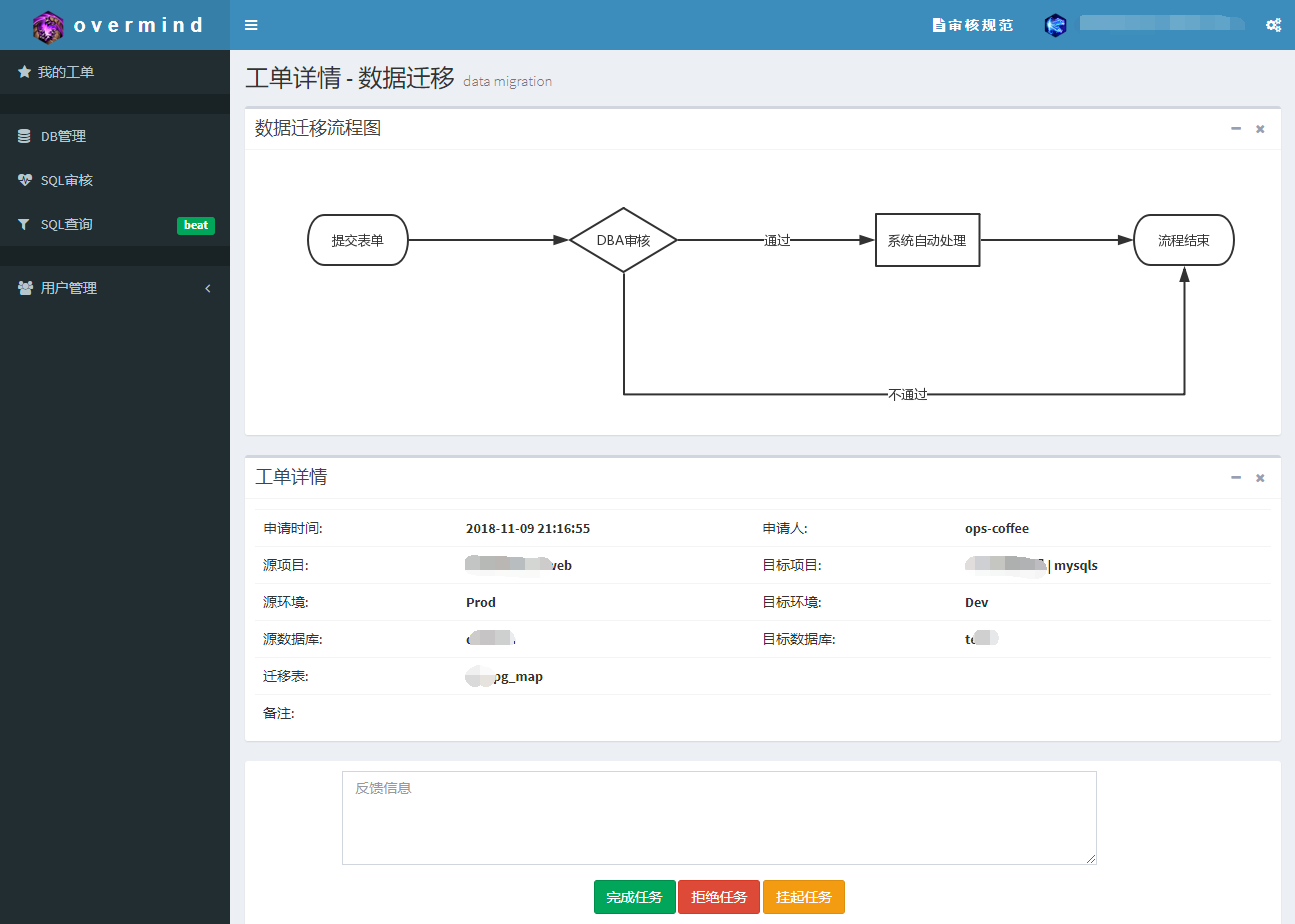
工单详情页:这里会详细记录这个工单的所有信息,提交、审核、执行的整个过程完整状态
写在最后
- 好的需求来源于日常的工作,重复的工作都可以自动化
- 关于数据库运维或者overmind有什么想法或建议欢迎交流
