Django配置Celery执行异步任务和定时任务
原生Celery,非djcelery模块,所有演示均基于Django2.0
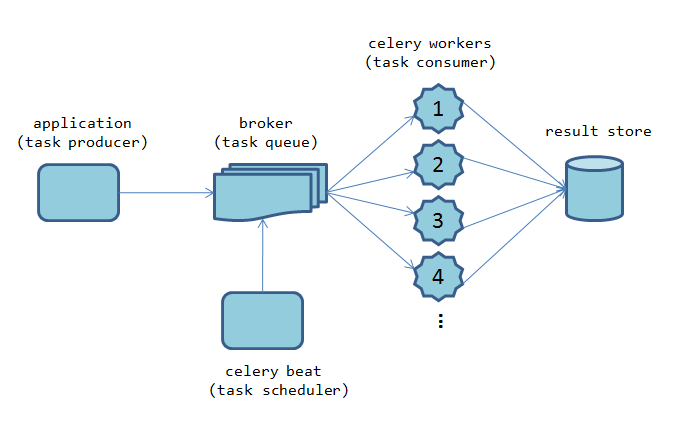
celery是一个基于python开发的简单、灵活且可靠的分布式任务队列框架,支持使用任务队列的方式在分布式的机器/进程/线程上执行任务调度。采用典型的生产者-消费者模型,主要由三部分组成:
- 消息队列broker:broker实际上就是一个MQ队列服务,可以使用Redis、RabbitMQ等作为broker
- 处理任务的消费者workers:broker通知worker队列中有任务,worker去队列中取出任务执行,每一个worker就是一个进程
- 存储结果的backend:执行结果存储在backend,默认也会存储在broker使用的MQ队列服务中,也可以单独配置用何种服务做backend
异步任务
我的异步使用场景为项目上线:前端web上有个上线按钮,点击按钮后发请求给后端,后端执行上线过程要5分钟,后端在接收到请求后把任务放入队列异步执行,同时马上返回给前端一个任务执行中的结果。若果没有异步执行会怎么样呢?同步的情况就是执行过程中前端一直在等后端返回结果,页面转呀转的就转超时了。
异步任务配置
1.安装RabbitMQ,这里我们使用RabbitMQ作为broker,安装完成后默认启动了,也不需要其他任何配置
# apt-get install rabbitmq-server2.安装celery
# pip3 install celery3.celery用在django项目中,django项目目录结构(简化)如下
website/
|-- deploy
| |-- admin.py
| |-- apps.py
| |-- __init__.py
| |-- models.py
| |-- tasks.py
| |-- tests.py
| |-- urls.py
| `-- views.py
|-- manage.py
|-- README
`-- website
|-- celery.py
|-- __init__.py
|-- settings.py
|-- urls.py
`-- wsgi.py4.创建website/celery.py主文件
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery, platforms
# set the default Django settings module for the 'celery' program.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'website.settings')
app = Celery('website')
# Using a string here means the worker don't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object('django.conf:settings', namespace='CELERY')
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
# 允许root 用户运行celery
platforms.C_FORCE_ROOT = True
@app.task(bind=True)
def debug_task(self):
print('Request: {0!r}'.format(self.request))5.在website/__init__.py文件中增加如下内容,确保django启动的时候这个app能够被加载到
from __future__ import absolute_import
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ['celery_app']6.各应用创建tasks.py文件,这里为deploy/tasks.py
from __future__ import absolute_import
from celery import shared_task
@shared_task
def add(x, y):
return x + y- 注意tasks.py必须建在各app的根目录下,且只能叫tasks.py,不能随意命名
7.views.py中引用使用这个tasks异步处理
from deploy.tasks import add
def post(request):
result = add.delay(2, 3)- 使用函数名.delay()即可使函数异步执行
- 可以通过
result.ready()来判断任务是否完成处理 - 如果任务抛出一个异常,使用
result.get(timeout=1)可以重新抛出异常 - 如果任务抛出一个异常,使用
result.traceback可以获取原始的回溯信息
8.启动celery
# celery -A website worker -l info9.这样在调用post这个方法时,里边的add就可以异步处理了
定时任务
定时任务的使用场景就很普遍了,比如我需要定时发送报告给老板~
定时任务配置
1.website/celery.py文件添加如下配置以支持定时任务crontab
from celery.schedules import crontab
app.conf.update(
CELERYBEAT_SCHEDULE = {
'sum-task': {
'task': 'deploy.tasks.add',
'schedule': timedelta(seconds=20),
'args': (5, 6)
},
'send-report': {
'task': 'deploy.tasks.report',
'schedule': crontab(hour=4, minute=30, day_of_week=1),
}
}
)-
定义了两个task:
- 名字为'sum-task'的task,每20秒执行一次add函数,并传了两个参数5和6
- 名字为'send-report'的task,每周一早上4:30执行report函数
-
timedelta是datetime中的一个对象,需要
from datetime import timedelta引入,有如下几个参数days:天seconds:秒microseconds:微妙milliseconds:毫秒minutes:分hours:小时
-
crontab的参数有:
month_of_year:月份day_of_month:日期day_of_week:周hour:小时minute:分钟
2.deploy/tasks.py文件添加report方法:
@shared_task
def report():
return 53.启动celery beat,celery启动了一个beat进程一直在不断的判断是否有任务需要执行
# celery -A website beat -l infoTips
1.如果你同时使用了异步任务和计划任务,有一种更简单的启动方式celery -A website worker -b -l info,可同时启动worker和beat
2.如果使用的不是rabbitmq做队列那么需要在主配置文件中website/celery.py配置broker和backend,如下:
# redis做MQ配置
app = Celery('website', backend='redis', broker='redis://localhost')
# rabbitmq做MQ配置
app = Celery('website', backend='amqp', broker='amqp://admin:admin@localhost')3.celery不能用root用户启动的话需要在主配置文件中添加platforms.C_FORCE_ROOT = True
4.celery在长时间运行后可能出现内存泄漏,需要添加配置CELERYD_MAX_TASKS_PER_CHILD = 10,表示每个worker执行了多少个任务就死掉
参考文章:
- http://docs.celeryproject.org/en/latest/
- https://github.com/pylixm/celery-examples
- https://pylixm.cc/posts/2015-12-03-Django-celery.html
