ELK日志系统之通用应用程序日志接入方案
前边有两篇ELK的文章分别介绍了MySQL慢日志收集和Nginx访问日志收集,那么各种不同类型应用程序的日志该如何方便的进行收集呢?且看本文我们是如何高效处理这个问题的
日志规范
规范的日志存放路径和输出格式将为我们后续的收集和分析带来极大的方便,无需考虑各种不同路径、格式的兼容问题,只需要针对固定几类日志做适配就可以了,具体的规范如下:
日志存放路径规范
- 项目日志只能输出到固定的位置,例如
/data/logs/目录下 - 同一类型(例如java web)的日志文件名保持统一,例如都叫
application.log - 一个类型的项目可以记录多个不同的日志文件,例如
exception.log和business.log
日志输出格式规范
- 日志输出必须为JSON格式,这个很重要
- 同一类型的项目应采用统一的日志输出标准,尽量将日志输出模块化,所有项目引用同一模块
- 输出日志中必须包含标准时间(timestamp)、应用名称(appname)、级别(level)字段,日志内容记录清晰易懂
日志信息级别规范
| 日志级别 | 说明 | 数值 |
|---|---|---|
| debug | 调试日志,日志信息量最多 | 7 |
| info | 一般信息日志,最常用的级别 | 6 |
| notice | 最具有重要性的普通条件信息 | 5 |
| warning | 警告级别 | 4 |
| error | 错误级别,某个功能不能正常工作 | 3 |
| critical | 严重级别,整个系统不能正常工作 | 2 |
| alert | 需要立刻修改的日志 | 1 |
| emerg | 内核崩溃等严重信息 | 0 |
从上到下级别依次从低到高,日志量从多到少,正确选择日志级别帮助后期快速排查问题
我们为什么要制定这样的规范?
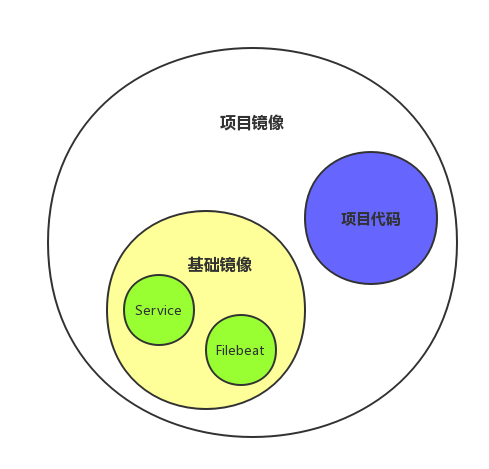
- 我们的项目都跑在Docker里,Docker镜像由基础镜像+项目代码组成
- 基础镜像打包了运行项目的基础环境,例如spring cloud微服务项目,则打包了jre服务
- 规范了日志存放及输出后,我们可以把作为日志收集agent的filebeat一并打包进基础镜像,因为同一类型项目的日志路径、格式都是一致的,filebeat配置文件可以通用
- 这样我们在后续的部署过程中就不需要关心日志相关的内容,只要项目镜像引用了这个基础镜像就能自动接入了我们的日志服务,实现日志的收集、处理、存储与展示
日志采集
我们通用日志采集方案如下图:
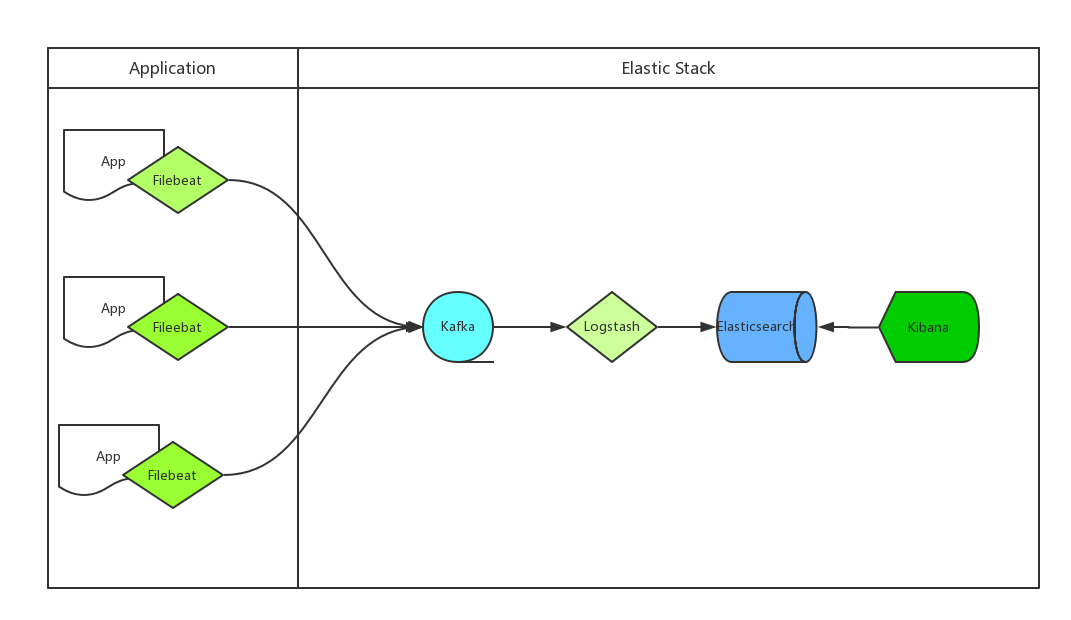
- 程序跑在容器里,容器内自带Filebeat程序收集日志
- 收集完成后传给kafka集群,logstash读取kafka集群数据写入elasticsearch集群
- kibana读取elasticsearch集群数据展示在web上,开发、运维等需要查看日志的用户登录kibana查看
Client端Filebeat配置
filebeat.prospectors:
- input_type: log
paths:
- /home/logs/app/business.log
- /home/logs/app/exception.log
json.message_key: log
json.keys_under_root: true
output.kafka:
hosts: ["10.82.9.202:9092","10.82.9.203:9092","10.82.9.204:9092"]
topic: filebeat_docker_javaKafka接收到的数据格式
{"@timestamp":"2018-09-05T13:17:46.051Z","appname":"app01","beat":{"hostname":"52fc9bef4575","name":"52fc9bef4575","version":"5.4.0"},"classname":"com.domain.pay.service.ApiService","date":"2018-09-05 21:17:45.953+0800","filename":"ApiService.java","hostname":"172.17.0.2","level":"INFO","linenumber":285,"message":"param[{\"email\":\"[email protected]\",\"claimeeIP\":\"123.191.2.75\",\"AccountName\":\"\"}]","source":"/home/logs/business.log","thread":"Thread-11","timestamp":1536153465953,"type":"log"}Server端Logstash配置
input {
kafka {
bootstrap_servers => "10.82.9.202:9092,10.82.9.203:9092,10.82.9.204:9092"
topics => ["filebeat_docker_java"]
}
}
filter {
json {
source => "message"
}
date {
match => ["timestamp","UNIX_MS"]
target => "@timestamp"
}
}
output {
elasticsearch {
hosts => ["10.82.9.205", "10.82.9.206", "10.82.9.207"]
index => "filebeat-docker-java-%{+YYYY.MM.dd}"
}
}都是基础配置很简单,不做过多解释,通过以上简单的配置就能实现任何应用程序的日志收集
日志展示
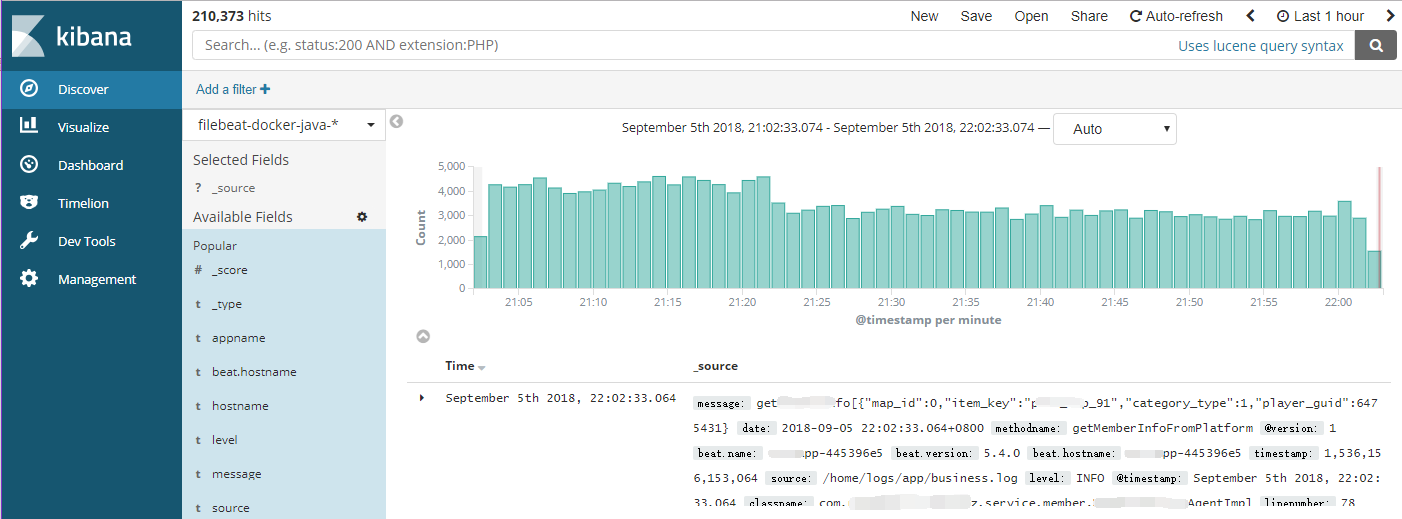
收集日志到elasticsearch之后,就可以通过kibana配置展示应用程序的日志了,方便开发及时发现问题,在线定位问题
写在最后
- 通用的基础与前提是规范,规范做好了事半功倍
- 日志打印Json格式不方便本地查看?这个可以把日志输出格式当做配置写在配置文件中,不同环境加载不同配置,就跟开发环境加载开发数据库一样
- 日志系统上线到现在稳定运行接近2年,除了刚开始有点不适应以为,都是越用越好用,现在他们已经离不开ELK日志系统了,大大提高了工作的效率
