多云系统之多云配置
多云系统的主要工作就是统一多云资源实现集中管理,同时基于关联关系来构建清晰的资源拓扑,为上层业务提供准确的基础数据。这里的核心功能主要有三个,分别是多云配置、资源管理和关系管理,上篇文章聊了其中关于关系管理的部分,合理的关联关系有助于构建清晰的资源拓扑。关系所关联的是资源,资源来源于云厂商,若要把云上资源同步到本地进行统一管理就是要用到多云配置实现的功能,这篇文章就来聊下多云配置
多云配置主要负责多云账号的管理以及云上资源的同步,整体流程如下
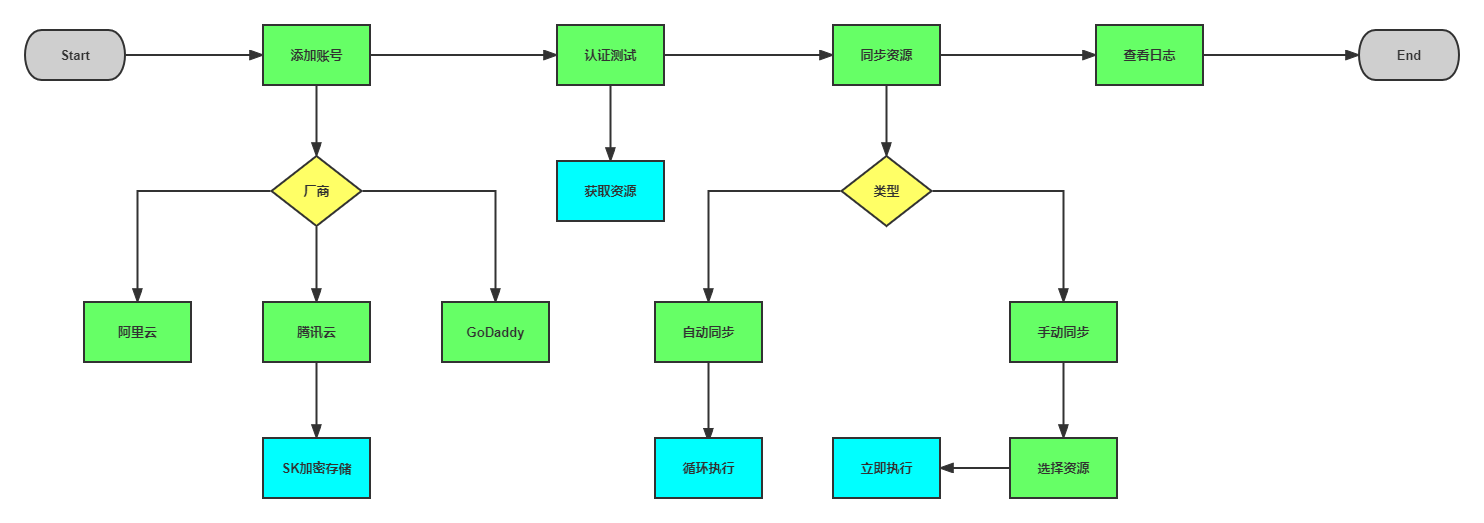
账号管理
获取云上资源需要云厂商提供的账号,对于账号不仅仅是简单入库了事,更要考虑到账号安全问题,关于账号安全有三点需要注意:最小权限、定期更新和加密存储。在云平台上创建账号配置权限时首先就保障满足基本需求即可,不要为了图省事给所有权限,账号一旦泄漏是非常危险,而对于多云系统来说其一要做到AKSK的加密存储,其二就是要方便更新,对于账号加密存储一般采用RSA/AES之类的加密方式进行加密即可,之前有好多篇文章专门写过加密可以参考,而对于方便更新的话就可以通过前端页面更新即可
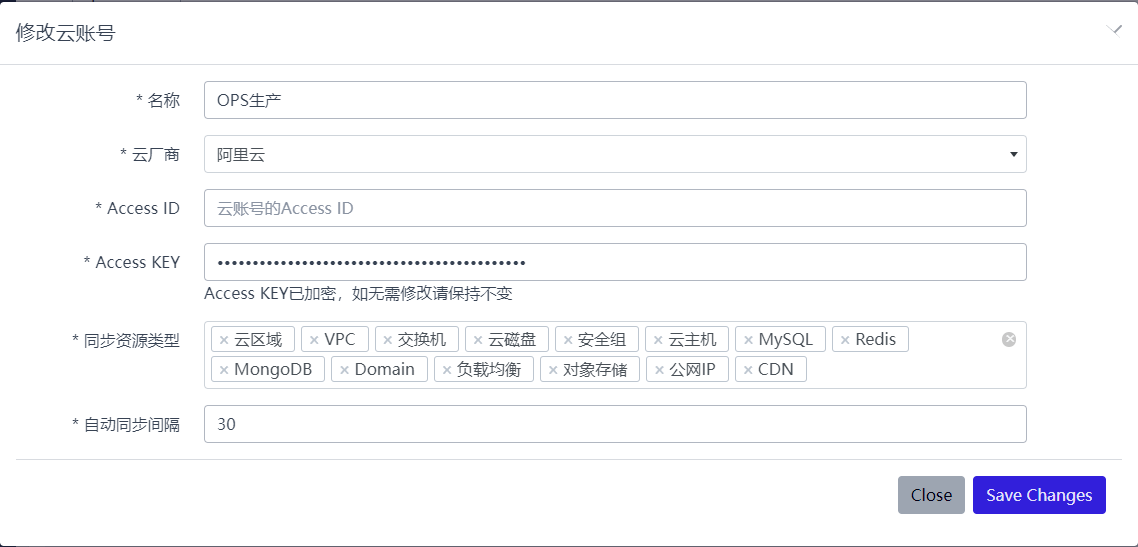
获取云资源所需的用户认证信息AKSK要保持定期更新,更新之后能顺便测试一下AKSK是否正确是很有必要的,为此我们有认证测试的功能,认证测试的原理是用更新的AKSK直接获取云上资源,能获取的到就表示正常,否则就要查下报错信息了,认证测试仅测试AKSK是否有效,对于更深层次的权限是否全部正确没有涉及
资源同步
不同的云厂商对相同的云资源提供的API和资源数据模型都是不同的,这对我们的使用造成了很大的困扰,而多云系统可以隐藏这些异构的资源数据模型和API差异,用户就像用一个云一样访问多云,这样大大降低了多云的复杂度,从而提升管理多云的效率
资源同步会将不同云平台不同云账号下的资源同步到本地进行统一的数据模型构建,无论是上层业务还是对外的API都可以基于统一的数据模型去处理,从而提供统一清晰的数据格式。这个过程中的主要工作就是通过不同云厂商的SDK/API获取云上资源数据,获取到的资源属于位于资源池,至于资源池有什么作用我们后续再说
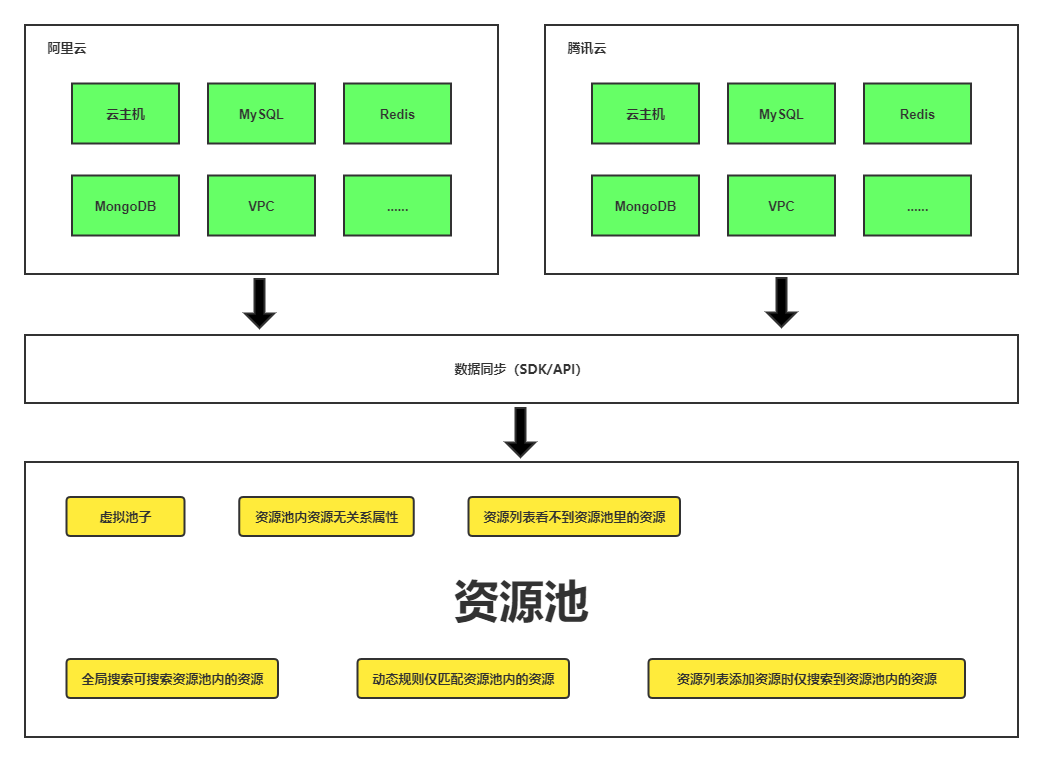
资源同步是个耗时的操作,并且需要不停的去同步,以保证本地资源属性的准确,所以对于资源同步借助于Celery的异步任务和定时任务来完成,默认每半小时会全量同步一下云上资源,所以本地资源跟云上资源状态会有半小时的时间差异,如果你修改了云上资源想要立即同步,也可以通过手动同步的方式主动触发同步
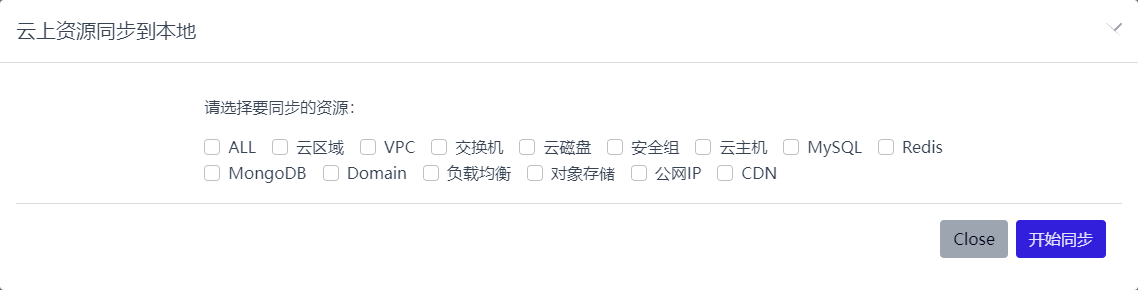
所有的同步结果都可以在同步日志里查看,无论是手动触发的同步还是定时执行的同步
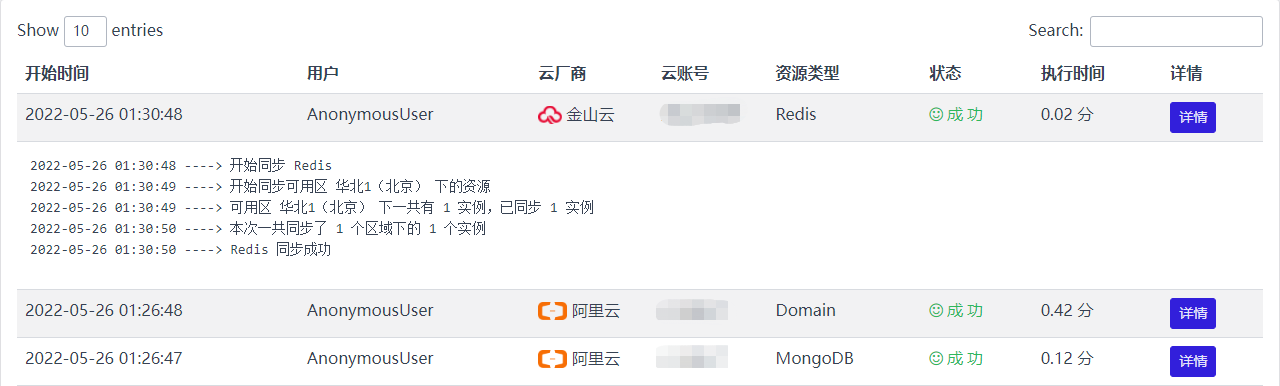
关于资源同步的重点和难点主要在本地数据模型的设计和云厂商返回数据的解析,这两者有着较强的关联关系,需要综合多个云厂商返回的数据来设计本地存储资源的数据模型,刚开始在设计模型的时候我希望记录的数据越多越好,这样就能展示更多的数据出来,但后边发现不同云厂商返回的数据差距较大,对于不同云厂商的异构数据模型记录的数据越多处理起来越麻烦,所以后边只记录用户展示的关键信息了,对于有查看资源详情需求的通过资源详情的API重新获取
吐槽与思考
当我第一天开始写代码的时候就听各种大佬在讲规范,代码规范、流程规范、结果规范,各大公司内部也会有详细且全面的规范文档,但本次在接各个云厂商的SDK时对这些规范的落地产生了深深的怀疑,怎一个乱字了得,更过分的是不仅乱还给下毒
举一个例子,对于返回数据有创建时间字段的,有的字段名叫CreateTime,有的叫CreatedTime,有的叫CreationTime,有的叫GmtCreated,有的返回UTC时间,有的返回本地时间,有的返回时分秒,有的仅返回时分,这些还都是同一家云厂商,只是不同接口而已
再举一个例子,获取分页数据,有个offset的参数,通常情况下都表示偏移量,但有些时候人家偏偏要让它表示页码pagenum,关键是同一个产品不同的接口同样都是offset参数,有的表示偏移量有的表示页码
这样的例子不胜枚举,处理的过程中非常消耗时间和精力,接了大小N个云厂商,每个都有这情况,没有例外。前车之鉴后事之师,这里也给自己提个醒,不仅要制定规范更要遵循规范,尽量不给用户造成太大的困扰
